
迈入千倍时代——算力天梯和算力年表(插图版)


GPU 系统的计算能力「又」超过 1 艾(exa,10 的 18 次方,百亿亿)了——NVIDIA 在 GTC 发布的 GB200 机柜,推理生成 token(FP4) 的速度达到 1.4 exaFLOPS(每秒浮点操作)。目前峰值性能达到 1 艾级别的超算,也只有 Top2 的美国橡树岭国家实验室的 Frontier 和美国阿贡国家实验室 Aurora。
如果你最近见过这条新闻,脑中可能会充满疑惑:好像 NVIDIA 去年就有超过 1 exa 的新闻?1 exa 是多大,意味着什么?怎么突然就这么快了?然后很快就忘了。
exa 是国际单位制(SI)中的「千倍」进制单位,我们对于 exa 这样的单位很容易感到陌生、远离现实生活、视而不见。
这不是因为我们平时接触的数目规模不够大,而是因为我们很少接触到以「千倍」为单位来看待数目规模的尺度。
传统增长
尺度是用来做比较和衡量变化的,而我们平时接触多的「比较和变化」——增长速度,通常都是:
- 「几倍」:二级市场(股市)整体的长期 beta 收益,年化 10% 左右,十年几倍
- 「十倍」:二级市场上最好的企业「十倍股」,通常是十年十倍,年化收益 25%
- 「几十倍」:VC 投资的初创企业一般要求 40% 以上增速,十年几十倍
- 「百倍」:摩尔定律,最有效的时候十年百倍(见下文年表)
而平时常说的、最厉害的「指数增长」,其实很多时候都是:以摩尔定律这类增速为底层基础、以初创公司这种增速为表象。
摩尔定律是线性的,在大部分时间也体现为一种线性的技术普及和市场扩张过程——技术成熟曲线(Hype Cycle)中平缓的斜坡和停滞期。


初创公司不是线性增长,但也不是一直加速,而是像创新扩散理论的 S 形曲线那样,只有中间是陡峭的。
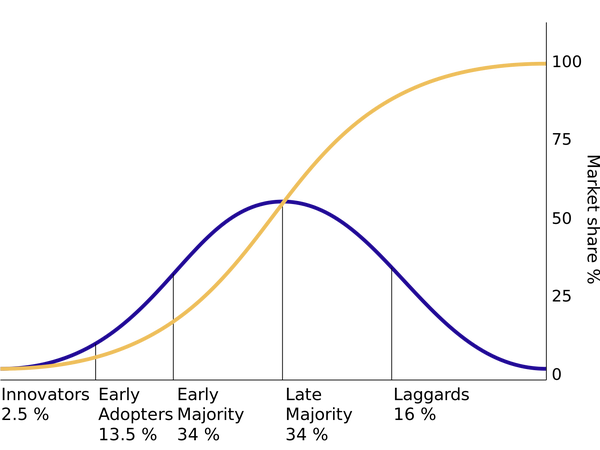

整体上一般就是每十年有几十到上百/几百倍的增长,跟真正以「千倍」单位为尺度的增长——「千倍增长」相比,其实要低一个档次(独角兽公司除外,可以达到千倍档次,因为有相同底层,见文末)。
那么「千倍增长」真的存在吗,如果存在,其中一定存在一些上述事物没有的、深层次的发展模式和趋势(想直接看结论可以跳到第四章节)。
研究方法
2024.3.24 更新
在后续内容之前先解释和剧透一下:
本文关注的算力演进趋势和增长模式,是以 AGI(通用人工智能)和 XR(元宇宙、增强现实)现在和未来所需计算量为终极目标的,比较的是各种算力类型/要素的「增速」满足最终需求的能力,不是关公战秦琼在面向不同用途、计算精度不同的东西之间「捧一踩一」。
本文的方法是:
- 先通过年表梳理每种算力类型自身不同型号的能力(标准基本一致)和年代
- 得到它们各自在每个十年中增速的粗略规模(比如年表中每个标题下备注的单位)
- 最后章节做分析的时候,先以十年为单位,分别回顾总结每种算力类型的增速、增速变化
- 根据年表中收集和突出的信息,给出增速差别和加速/放缓背后的原因
- 再比较不同算力类型的增速。把它们增速背后各自不同的原因,归纳到相同的增长模式/增长曲线里
- 提出「加速计算」新增的「第三增长曲线」,指出这种增长模式跟「千倍增长(增速)」的关系、跟 AGI 的关系
最后也顺便总结了独角兽企业增长模式跟「第三增长曲线」的共通之处。
把早期计算机、HPC/超算跟 GPU 放到一起比较「增速」,是为了归纳和突出之前的主流增长模式(「第一增长曲线」和「第二增长曲线」)。
为了看清「第三增长曲线」这样的根本模式和大的发展趋势,本文看问题的角度是有意「粗略」(粗粒度)的,以十年和千倍进制为尺度,尽量拉平小尺度中的波动、周期和细节。
算力千倍天梯
为了方便理解这种尺度/增长,我做了一个表格,以国际单位制(SI)中的「千倍」单位制为脉络和层级,填入每个层级对应的事物(黄色部分都跟计算机的算力有关,是目前算力已经触达的层级):
如果下面的图不能放大,可以看这个表格的飞书版
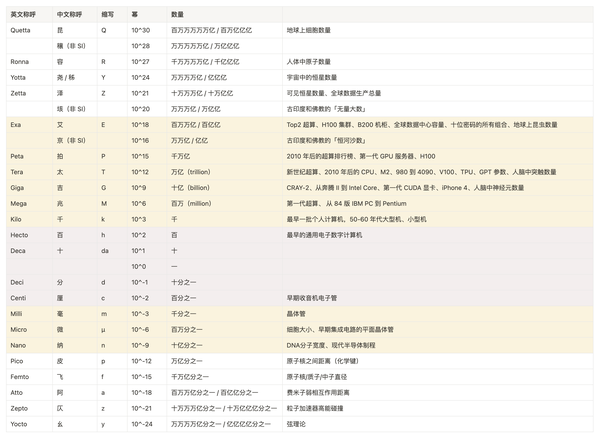

这个天梯中,各种事物达到某个「千倍」层级的时间无法体现。
所以我又整理了一条时间线,可以看到这些事物在每个时期达到的千倍层级:
算力十进制年表
上世纪 40 年代
制程:cm
通用计算:h
战争加速了电子管的技术发展和生产。
46 年第一台数字的(之前有基于物理模拟的计算机)、电子的(之前有机电式的)、通用的图灵完备的(可编程)计算机 ENIAC 被美国陆军投入使用,包含上万个电子管,占地上百平米,运算能力相当于现代的 500 FLOPS(每秒 500 次浮点数计算)。


上世纪 50 年代
制程:mm
通用计算:K
电子管广泛应用于民用产品,比如收音机。小型电子管被大量生产,尺寸十几到几厘米。
50 年代中期,47 年发明的晶体管(尺寸以毫米为单位)开始取代电子管的主导地位。


52 年第一台商用大型机 UNIVAC I 交付美国人口调查局,每秒可执行 1905 次运算操作。




55 年首款全晶体管商用大型机 IBM 608 发布。59 年经典的 IBM 1401 发布,每秒执行 86957 次指令(时钟周期),两个 10 位数的加法运算每秒 2000 多次,20 位数加法每秒 1000 多次。






硅谷诞生:
51 年斯坦福建立工业园,晶体管之父肖克利 53 年离开贝尔 56 年来到山景城。


57 年 8 名工程师辞职创立仙童半导体。


上世纪 60 年代
制程:μm (*10)
通用计算:K (*10)
高性能计算:M (*10)
集成电路开始商用和普及(59 年仙童创始人诺伊斯发明实用化集成电路),其中的平面晶体管尺寸在 10 微米以上,一块芯片几个晶体管,60年代中后期做到一块芯片上百个晶体管。


64 年使用混合集成电路的第三代计算机 IBM 360(大型机)上市,速度达到 34500 IPS(每秒执行指令次数),用于高性能计算的型号(Model 91)可达到 16.6 MIPS(每秒执行 1660 万次指令)。




60 年 DEC 的全晶体管小型机 PDP-1 展示。


65 年 PDP-8 上市,低复杂性低成本,采用简单指令集提高执行速度,运算能力跟 IBM 360 相近。小型机开始普及。




65 年摩尔定律诞生。
68-69 年仙童员工辞职创立 Intel 和 AMD。


上世纪 70 年代
制程:μm
通用计算:K (*100)
超算:M (*100)
早期个人计算机诞生:
74 年 Altair 8800 发布。


75 年家酿俱乐部首次聚会。


76 年 Apple I 展示。


77 年 Apple II($1298,相当于现在的 43000 人民币)和 Commodore PET($795,相当于现在的 26000 人民币)上市。




Apple II 和 PET 使用的 MOS 6502 芯片(Atari 2600 和 NES 红白机也用这种芯片)制程 8 微米,含 4000 多个晶体管,整数运算能力 0.43 MIPS(每秒 43 万次操作)。






随着芯片制程从 10 微米发展到 3 微米,一块芯片上的晶体管数量从上千发展到几万(大规模集成电路)。
比如 78 年发布的 Intel 8086,3 微米制程,含 29000 个晶体管,运算能力 0.33 MIPS(每秒 33 万次操作)。
带来的成本降低和小型化推动了之后 80 年代个人计算机的普及。


性能也逐步提升(虽然不是这一时期的重点),比如 79 年的 Intel 8088 和 摩托罗拉 68000 运算能力开始接近和超过 1 MIPS(每秒一百万次操作)。
76 年第一台商业超算诞生,CRAY-1 性能达到了 160 MFLOPS(每秒 160 万次浮点操作)。


上世纪 80 年代
制程:μm
通用计算:K (*100) -> M (*10)
超算:G
个人计算机开始普及:
81 年第一代 IBM PC 上市($1565,相当于现在的 35000 人民币)。使用 Intel 8088 芯片,运算能力 0.75 MIPS(每秒 75 万次操作)。


82 年 Commodore 64 上市($595,相当于现在的 12000 人民币)。






83 年 Apple 发布第一台 GUI(图形用户界面)个人电脑 Lisa($9995,相当于现在的 20 万人民币)。
84 年 Apple 发布 Macintosh($2495,相当于现在的 49000 人民币)。









84 年 IBM PC 采用 Intel 80286 芯片,1.5 微米制程,十几万晶体管,运算能力最快超过每秒两百万次(1.28 - 2.66 MIPS)。




86 年 80386(之后更名为 i386)上市,1 微米制程,27 万晶体管,运算能力 4 - 7 MIPS。
89 年 i486 上市,0.8 微米制程,含一百多万晶体管,运算能力最快可达每秒 4 千万次(41 MIPS)。




85 年投产的超算 Cray-2,峰值性能达到 1.9 GFLOPS。


上世纪 90 年代
制程:μm (*0.1)
通用计算:M (*100) -> G
超算:G (*100) -> T
93-95 年奔腾(Pentium / 586)发售 0.8 微米、0.6 微米、0.35 微米制程的型号,晶体管数量三四百万,运算能力超过每秒 1 亿次(188 MIPS)。



97-99 年奔腾 II、奔腾 III 发售了 0.35 微米、0.25 微米、0.18 微米制程的型号,晶体管数量 750 万到 950 万,运算能力几百到几千 MIPS(2054 MIPS)。










93 年的超算 CM-5 峰值性能达到 130 GFLOPS。




97 年美国政府超算计划(ASCI)的第一台机器 Red 的峰值性能首次达到 1 太(tera,TFLOPS)。


通用 GPU 的前身——3D 图形加速卡(无通用计算能力)开始出现:
96 年 Voodoo 发布。


97 年 NVIDIA 最早的 3D 加速卡 RIVA 128 发布。


98 年 Voodoo 2 和 NVIDIA RIVA TNT 发布。99 年 TNT2 发布。










本世纪 00 年代
制程:nm (*10)
通用计算:G (*10)
加速计算:G (*100)
超算:T (*100) -> P
PC 的 CPU 性能进入 G 时代。
纳米级别的制程技术出现,03-05 年间,90 纳米制程被商业化。
04 年采用 90 纳米制程的奔腾 4 包含的晶体管数量超过 1 亿,处理能力超过 9000 MIPS(9G)。






06-07 年 Intel Core 和 AMD Athlon 64 发布,采用 65 纳米制程, 进入多核时代,处理能力超过 10000 MIPS(10G),大约相当于 40 GFLOPS。


GPU 诞生,开始通用化:
99 年 10 月 NVIDIA 发布初代 GeForce(初代 GPU),采用台积电 220nm 制程,通用计算能力(单精度浮点数/FP32)是 960 MFLOPS。


00 年 8 月第二代 GeForce 的计算能力翻倍达到 2 GFLOPS。这时老黄已经提出了超越摩尔定律——英伟达的产品每 6 个月性能翻一番。
01 年 2 月第三代 GeForce 采用台积电 150nm 制程,计算能力达到 10 GFLOPS(半年翻两番…)。
GeForce3 是第一款支持 shader 编程的显卡。非官方的 GPGPU(通用 GPU)研究开始兴起。


06 年 NVIDIA 发布的第八代 GeForce 做了重大的微架构(芯片内部架构)更新,新的 Tesla 架构把 3D 渲染中的顶点和像素管线的处理器统一成 Unified Shader 处理器,使其也可以用于通用计算,称作 CUDA Core,CUDA 1.0 SDK 随之发布,首次支持 C 语言开发。




其中 8800 采用 90 纳米制程(07 年 8800GT 采用 65 纳米),接近 7 亿晶体管,计算能力超过 300 GFLOPS(5 年 10 倍)。


02 年日本的地球模拟器成为最快超算,峰值性能 40 TFLOPS。


04 年 IBM 的蓝色基因登顶,之后扩展达到几百 TFLOPS 的性能。



08 年 IBM Roadrunner 峰值性能首次超过 1 petaflops,超算进入 P 时代




本世纪 10 年代
制程:nm (*10)
桌面通用计算:G (*100) -> T
移动加速计算:G -> G (*100)
桌面加速计算:T (*10)
数据中心加速计算:T (*100) / P
超算:P (*10) -> P (*100)
10 年 Apple 发布 iPhone 4 和 iPad,使用自研处理器 A4,单核 CPU + 单核 GPU,采用三星 45nm 制程,GPU 计算能力 6 到 8 GFLOPS。


18 年发布的 A12(6 核 CPU,4 核 GPU)和 A12X(8 核 CPU,7 核 GPU)采用台积电 7nm 制程,A12 的 FP32 计算能力超过 500 GFLOPS,用于初代 iPad Pro 的 A12X,FP32 计算能力超过 1 TFLOPS。


从 09 年到 19 年,Intel 发布了 9 个代际的酷睿 CPU,制程从 32nm 到 14nm,包含 20 亿以上晶体管(单核),第一代的 i7 990X 计算能力最高超过 170 GFLOPS,第九代的 i9 9900 计算能力最高超过 1000 GFLOPS(1T)。


10 年 NVIDIA 发布了「GPU Computing」的下一个重大微架构更新,新的 Fermi 架构改进了对双精度浮点运算的支持,对科学计算等领域更友好。
12 年,依靠 GPU 克服计算成本(算法用 CUDA 在两块 NVIDIA 显卡上编写)的深度学习模型 AlexNet 夺得 ImageNet ILSVRC(大规模视觉识别挑战) 冠军,错误率远低于第二名。论文发表后反响巨大影响深远,深度学习进入爆发增长阶段,机器学习进入 GPU 时代。


15 年 NVIDIA 发布 Maxwell 架构的 GeForce GTX 旗舰 980 TI, 台积电 28nm 制程,计算能力超过 5 太(5 TFLOPS)。




16 年 NVIDIA 发布 Pascal 架构和面向服务器的「数据中心 GPU」 P100,新架构支持半精度(FP16)运算——开启了「减少浮点数精度」这条重要的性能提升曲线和护城河(不过这个架构中 FP16 还不能带来很多计算速度提升,主要是减少内存和带宽占用,支持更大的模型)。
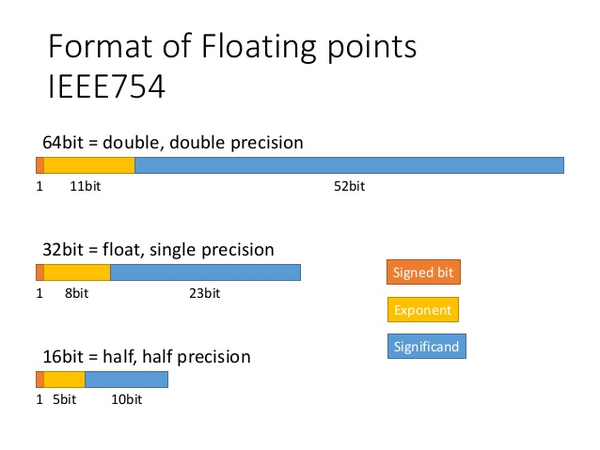

此外还支持 NVLink 1.0,开启了另一条重要的性能提升曲线和护城河「多卡协同」。


17 年发布了 Pascal 架构的 1080 Ti,三星 14nm 制程,计算能力超过 10 TFLOPS,正式支持 PC VR。


17 年 NVIDIA 更重要的发布是 Volta 架构,首次引入为 AI 运算优化的、支持 FP16 的 Tensor Core。


新架构下的「数据中心 GPU」 V100(第一代 AI 卡皇),采用台积电 12nm 制程。FP32 计算能力达到 14 TFLOPS,深度学习计算能力(FP16)超过 100 TFLOPS。


16 年 NVIDIA 发布第一款 GPU 服务器——DGX-1,包含 8 块 Pascal/Volta 架构的 GPU。18 年发布的 DGX-2 包含 16 块 V100,性能达到 2 petaFLOPS。GPU 平台进入 P 时代。


16 年 Google 也发布了专用于 AI 的芯片(ASIC)——TPU,支持低精度(8位)上的大量运算,第一代 TPU 的运算能力达到 92 TFLOPS,18 年发布的第三代 TPU 的运算能力达到 275 TFLOPS。




这个时期的顶级超算普遍开始依赖 GPGPU:
12 年 Cray 给橡树岭国家实验室制造的 Titian,计算速度超过 10 petaFLOPS(理论峰值 27 petaFLOPS),包含 18688 块 NVIDIA GPU。


16 年不含 GPU 的神威太湖之光成为最快超算,计算速度超过 100 petaFLOPS。两年后就被橡树岭国家实验室接替 Titian 的 Summit 超越,计算速度达到 200 petaFLOPS,包含 27648 块用 NVLink 连接的 V100。


本世纪 20 年代
制程:nm
桌面通用计算:T -> ?
移动加速计算:T -> ?
桌面加速计算:T (*10) / T (*100) -> ?
数据中心加速计算:P / E -> ?
超算:E -> ?
移动端加速计算:
23 年 Apple 发布 A17 Pro,台积电 3nm 制程,6 核 CPU,6 核 GPU,16 核 NPU,190 亿晶体管,FP32 计算能力超过 2 TFLOPS。


Vision Pro 使用的 M2 芯片,8 核 CPU,10 核 GPU,16 核 NPU,FP32 计算能力超过 3.5 TFLOPS。


桌面加速计算:
NVIDIA 在 18 年发布 2080 TI(Turing 架构),20 年发布 3090(Ampere 架构),22 年发布 4090(Ada Lovelace 架构)。单精度(FP32)计算能力发展到 82 TFLOPS,深度学习(FP16)计算能力发展到 330 TFLOPS。


数据中心加速计算:
NVIDIA 在 20 年发布 A100(Ampere 架构),新的 Tensor Core 3.0 支持 TF32、BF16 精度,稀疏矩阵运算速度翻倍。


22-23 年发布 Hopper 架构 的 H100 和 H200,新的 Tensor Core 4.0 支持比 FP16 更小的 FP8,提供 Transformer Engine 简化 FP8 的使用。
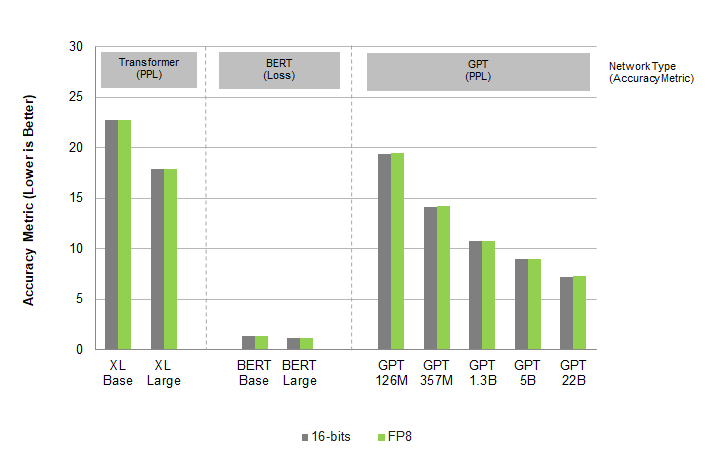

H100 的 FP32 计算能力发展到 67 TFLOPS,TF32 的深度学习计算能力达到 989 TFLOPS,FP8 的深度学习计算能力接近 4 petaFLOPS。
23 年 Google 最新的第五代 TPU,计算能力是 393 TFLOPS。
8000 张 H100 可以在 90 天里训练出 GPT-4 这样参数超过 1 太(tera,相当于trillion/万亿)的模型(GPT-MoE-1.8T)。


Ada Lovelace 架构的 4090 具备同样的 Tensor Core,支持 FP8,只是不支持卡间互联(NVLink)这类数据中心场景的必杀技。
这次 GTC 发布的 Blackwell 架构 GPU(B200),FP8 计算能力达到 10 petaFLOPS,新支持的 FP4(适合推理)计算能力达到 20 petaFLOPS,是 H200 的 5 倍。在 90 天里训练出 GPT-4 只需要 2000 张 H200。


22 年的单台 GPU 机柜(DGX GH200,包含 32 块 H100),FP8 计算能力达到 128 petaFLOPS,需要 8 台机柜组成的集群(包含 256 块 H100),才能达到 1 艾(exaFLOPS)。


这次 GTC 新发布的 GB200 NVL72(包含 72 块 Blackwell 架构的 B200),一台机柜的计算能力(FP4)就已经超过 1 艾(1.4 exaFLOPS),用于训练的 FP8 计算能力达到 720 petaFLOPS。


组成集群(GB200 NVL72 Compute Rack)后包含 576 块 GPU:


再组成整个数据中心,包含 32000 块 GPU,运算能力达到 645 exaFLOPS。


目前运行中的排名前二的超算,峰值性能也只是刚超过 1 艾:
美国橡树岭国家实验室的 Frontier,峰值性能 1.67982 exaFLOPS。


美国阿贡国家实验室的 Aurora,峰值性能 1.09 exaFLOPS。


千倍增长
第一增长曲线
根据以上梳理可以看到:
算力最初只有一条增长曲线,就是算力硬件的本体——半导体制程。
半导体制程最初以十年十倍的速度改进。
到了 70 年代放缓,似乎是因为这一时期更侧重小型化和降低成本。
80 年代恢复十倍速度。
00 到 01 年代再度放缓,因为已经接近 n(纳米)这个单位的边界,开始要进入 p(皮米)这个在物理上达到原子尺寸的层级。
第二增长曲线
「通用计算」(CPU、通用计算机)的性能,最初同样以十年十倍的速度发展。
80 到 90 年代在硅谷诞生、个人计算机普及(可以认为是来自市场侧的增长曲线)和摩尔定律的支撑下,提升到百倍。
00 到 01 年代不但没跟着半导体制程放缓,反而加速到百倍。
原因是通用计算不再只依赖半导体制程这条属于「垂直扩展」的增长曲线,增加了以多核、大小核、SoC 为代表的「水平扩展」增长曲线。


第一种千倍增速
到了超算这里,第一种「千倍增长」出现了。
超算从一开始就有前面说的两条增长曲线。
其中的「垂直扩展」的增长曲线,在 80 - 90 年代刚好叠加上了个人计算机发展带来的摩尔定律红利(百倍)。
因此从 80 年代开始就进入每十年千倍的增长阶段。
不过可以看到这种增速更多由能投入大量资源的头部超算来维持。可能因为超算的「水平扩展」是非标准、非规模化的,成本较高。
进入 10 年代,超算的增速也放缓到百倍/十倍。
这种千倍增速有点像部分独角兽企业,暂时叠加了市场红利,但自身存在固有问题,千倍增速难以维持。
第二种千倍增速
最后再看「加速计算」(GPU),把桌面端、移动端、数据中心等各种加速计算的场景一起看待,加速计算从 00 年代诞生开始就一直保持千倍增速至今,且没有放缓迹象(甚至有所加速)。
这种千倍增速的维持乃至加速,正好迎合了 AGI 时代的需求:




上图中 AI 模型需要的运算速度爆发增长的起点,就是前文介绍过的 AlexNet 事件,从此之后模型的层数规模、参数规模进入了「水平扩展」时代,需要相应的运算速度增长。而且正好也达到了艾(exaFLOPS)的级别。
双生的第二增长曲线
要解释加速计算这种千倍增速的维持甚至加速,同样需要看清它有哪些增长曲线。
加速计算有「垂直扩展」的半导体制程这条增长曲线,且既幸运又必然的没受到 x86 架构和 Intel 的影响。
加速计算有两条「水平扩展」增长曲线:
跟「通用计算」风格类似的「水平扩展」增长曲线——比如多核、SoC。
跟超算风格类似的「水平扩展」增长曲线——基于 NVLink 的芯片间互联协同、基于 NVSwitch 的服务器之间协同。
这种协同不同于超算,是标准化、规模化的。这既带来低成本,也带来可扩展性。
由于「垂直扩展」增长曲线的物理瓶颈,能维持/加速「水平扩展」的可扩展性,变得至关重要(特别是对 AGI 来说)。






不过仅凭这种「双生」和「可扩展」,可能还不足以维持千倍增长。
仔细看下年表,会发现加速计算还有更多增长曲线:
第三增长曲线
GPGPU 虽然是「通用」的,但定位是加速计算,针对那些能超高密度并行计算的部分做加速。最初只是 3D 图形渲染和少数科学/工程计算符合这种要求。
深度学习和 AGI 时代带来的变化是,大量原本要手工灵活编写代码逻辑的需求、越来越多无法手工写代码实现的需求,被通过类似「涌现」这样超出人类思维能力的转换过程,提取出了相同的、可以高密度并发重复计算的部分。
除了导致 GPGPU 的需求大增,也凭空增加了大量的「相同」——有相同特点的数据类型、算法类型,让 GPGPU 能发挥自己的长处,对它们分而治之,做专门优化。
GPU 的起源就是针对像素渲染、顶点着色等「相同」的数据/算法做专门优化。
优化方法包括:
硬件手段——比如在 GPU 微架构中增加专门的处理单元。
NVIDIA 频繁的升级「微架构」,就是这种手段的体现。


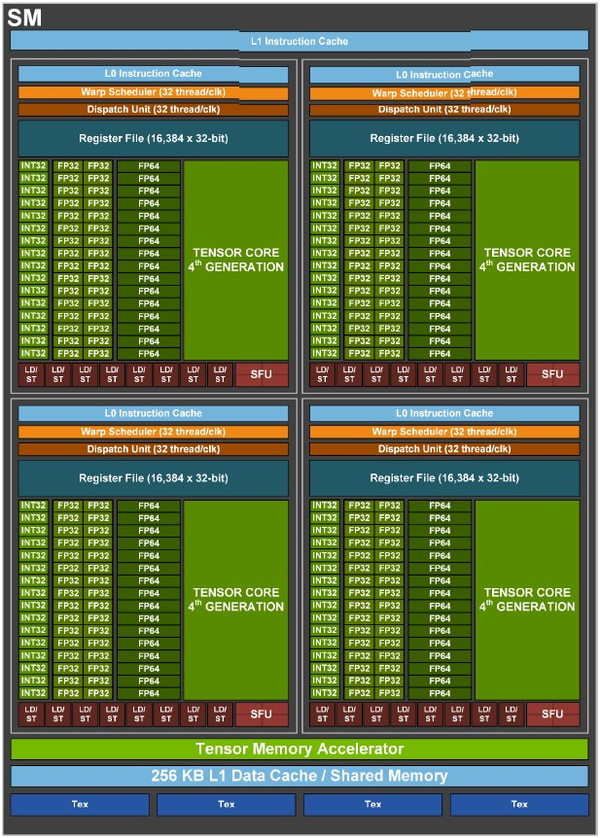

SDK 手段——进入开发者那一侧,改变他们写代码的方式,增加各种有硬件优化的「相同」部分,掌控这些「相同」的形式(比如数据格式、API 抽象等),让它们符合自己的标准。
前面介绍过的 FP16、TF32、FP8、FP4 等「减少浮点数精度」,乃至整个 CUDA,都属于这类。


SDK 手段也可以称作软件手段、算法手段。
以上两种手段都还依赖算法和芯片协同、软硬一体化协同。
跟普通硬件产品的软硬一体化协同相比,包含了 SDK 的软件手段能影响开发者体验(DX)和开发方式,是远远更强大的协同。
这也意味着越强大的软硬协同中的软件部分,会趋向大幅多于硬件部分。
总之,第三增长曲线跟第二增长曲线(水平扩展)有类似之处,在一个领域里,「相同」事物越多,就越容易分而治之和专门对待,越容易重复和并行,重复和并行也是一种水平扩展。另一方面,软件和硬件协同越强、软件越强,就越能利用这种「相同」和水平扩展的机会。
最后也顺便看看独角兽(千倍增速)的特点:多个增长曲线、有内部和外部双生的水平扩展要素(比如网络效应)、面向的市场需求中的「相同」部分不断自然增加或可以主动增加、软件强大、能用软件做协同、有开发者平台、开发者体验优先
